On ne prompt pas pareil un LLM basique, un agent d’IA et un mode recherche approfondie
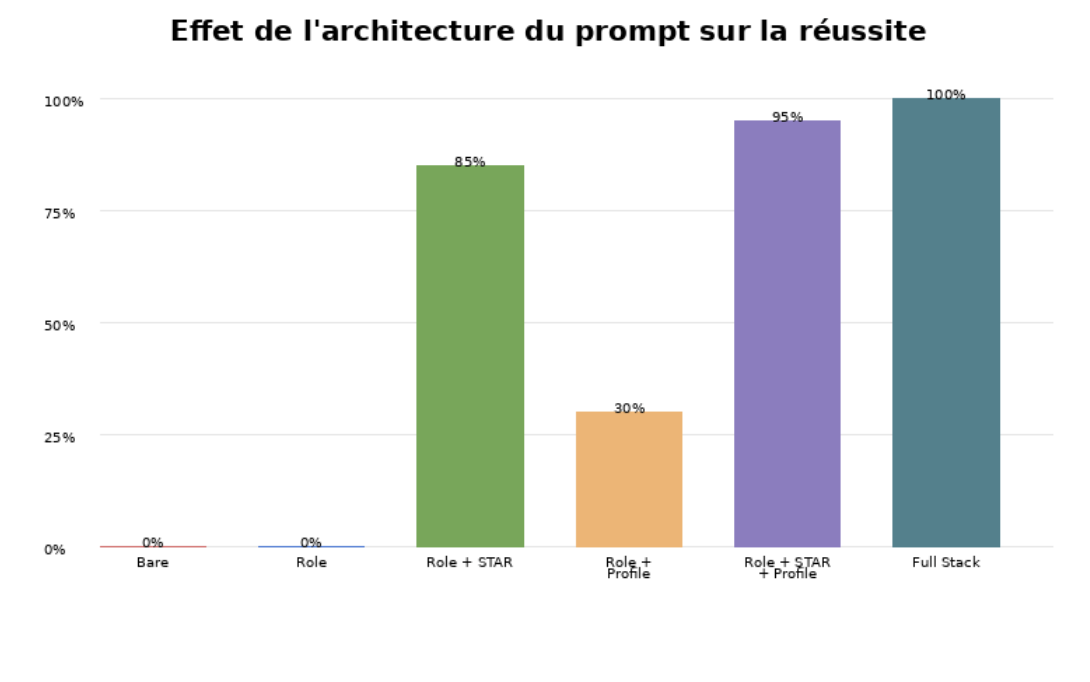
Avant de choisir une technique de prompting, il faut d’abord savoir à quel type de système on parle. C’est l’erreur la plus fréquente chez les débutants. Ils appliquent la même logique de consigne à un LLM ponctuel, à un agent outillé et à un mode de recherche approfondie, alors que ces trois régimes de travail n’attendent pas le même niveau de cadrage.
1. Identifier le système. 2. Définir le niveau d’autonomie attendu. 3. Choisir ensuite la famille de prompt adaptée. Sans cette étape, le comparatif Zero-shot, Few-shot, CoT et CARE perd une partie de son sens.
| Type de système | Logique de travail | Ce qu’il faut préciser dans le prompt | Erreur fréquente | Bonne pratique |
|---|---|---|---|---|
| LLM basique | Réponse directe à une consigne ponctuelle. | Objectif, contexte immédiat, format attendu, contraintes de ton et de longueur. | Empiler des demandes contradictoires dans un seul message. | Faire court, net, observable, avec sortie vérifiable. |
| Agent d’IA | Boucle plus outillée avec rôle, workflow, outils, vérification, parfois mémoire. | Mission, responsabilités, outils autorisés, critères d’arrêt, tests, validation, gestion des erreurs. | Le traiter comme un simple chatbot sans lui donner le cadre opératoire. | Écrire un brief de mission, pas seulement une question. |
| LLM en recherche approfondie | Travail itératif orienté collecte, recoupement, hiérarchisation et restitution sourcée. | Périmètre, niveau de preuve attendu, sources prioritaires, forme du livrable, gestion des incertitudes. | Demander une conclusion définitive avant d’avoir défini le protocole de recherche. | Donner une question, un protocole, des critères de sélection de sources et une structure finale. |
Un LLM basique répond. Un agent exécute une mission. Un mode recherche approfondie enquête puis synthétise. Plus le système agit, plus le prompt doit préciser le rôle, la méthode, les outils, les critères de contrôle et la manière de traiter l’incertitude.
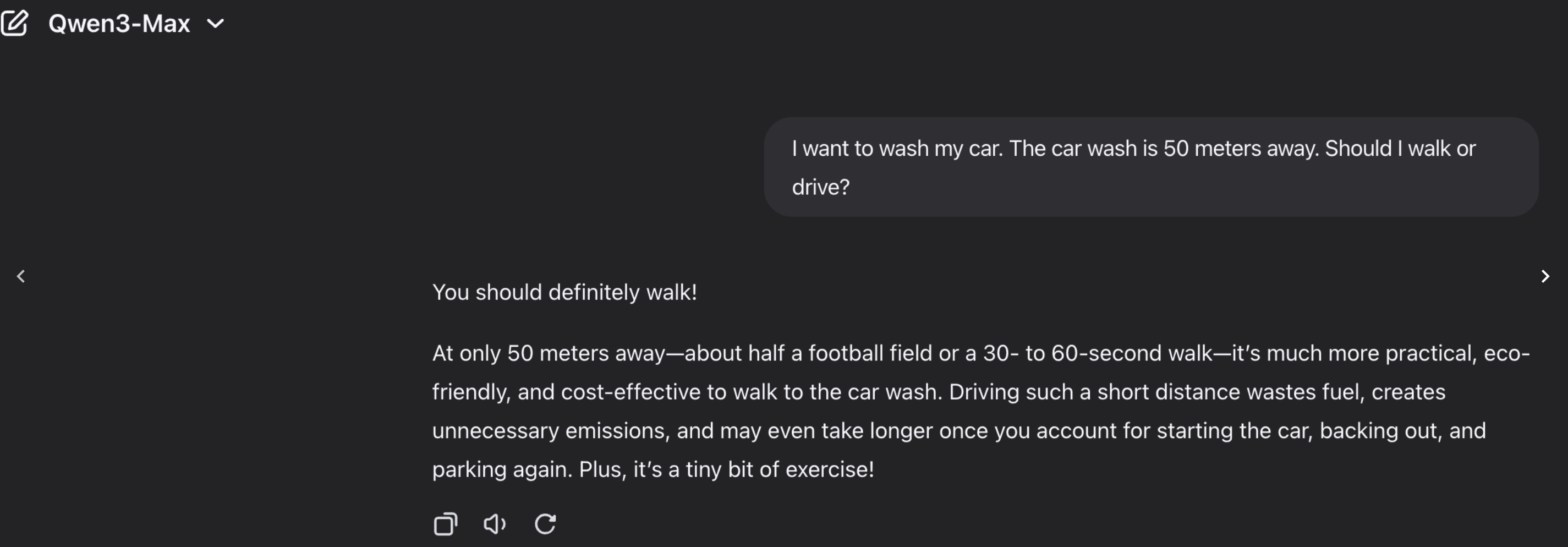
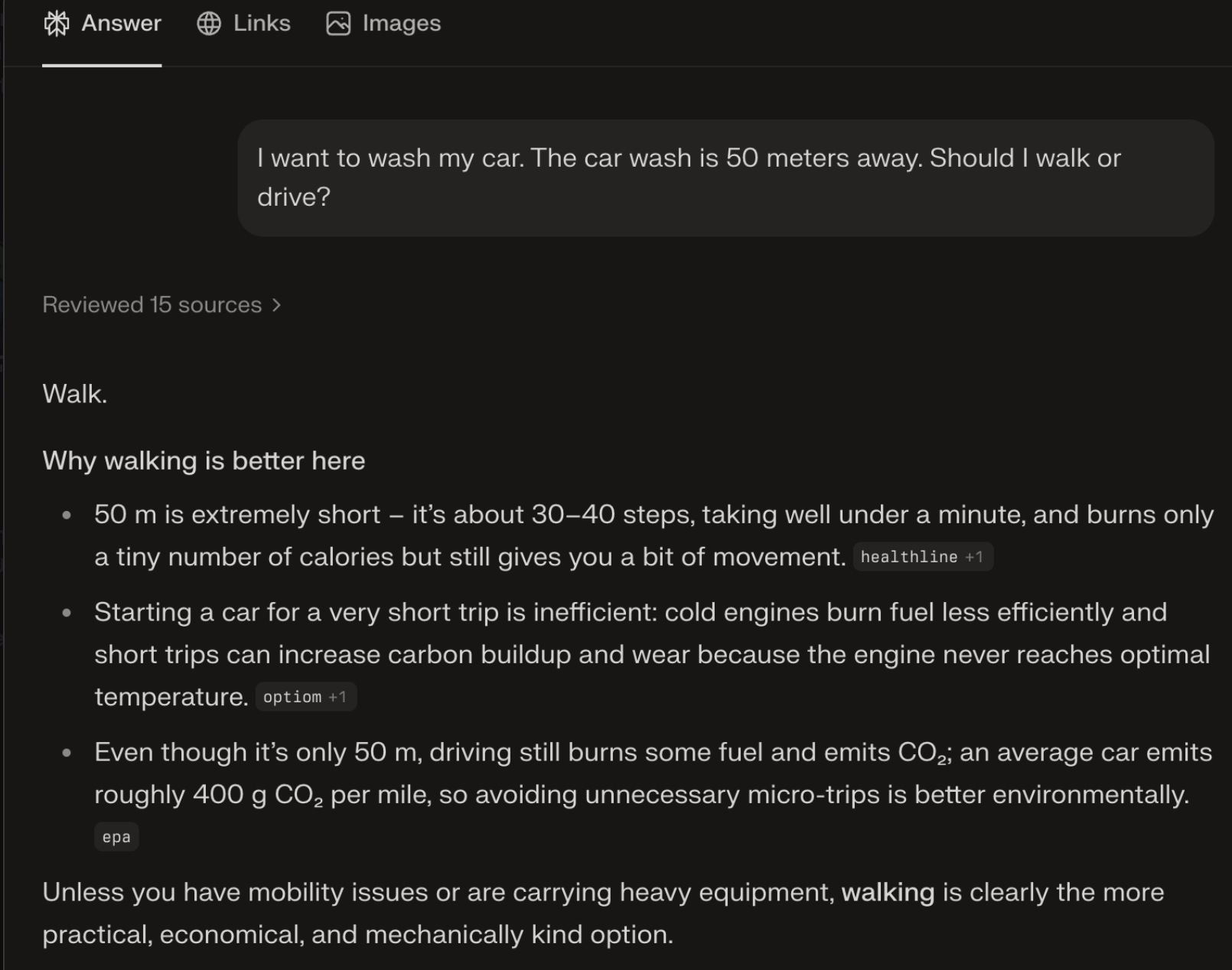
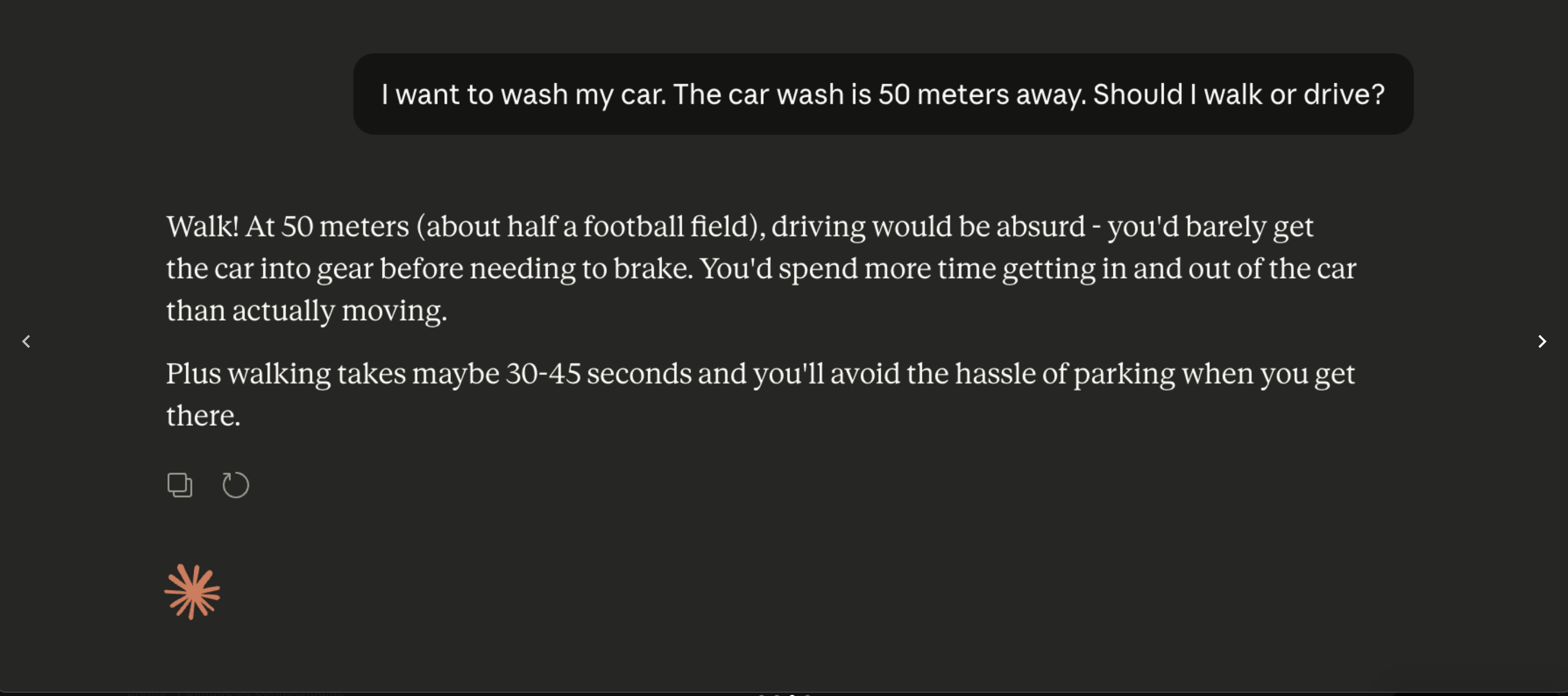
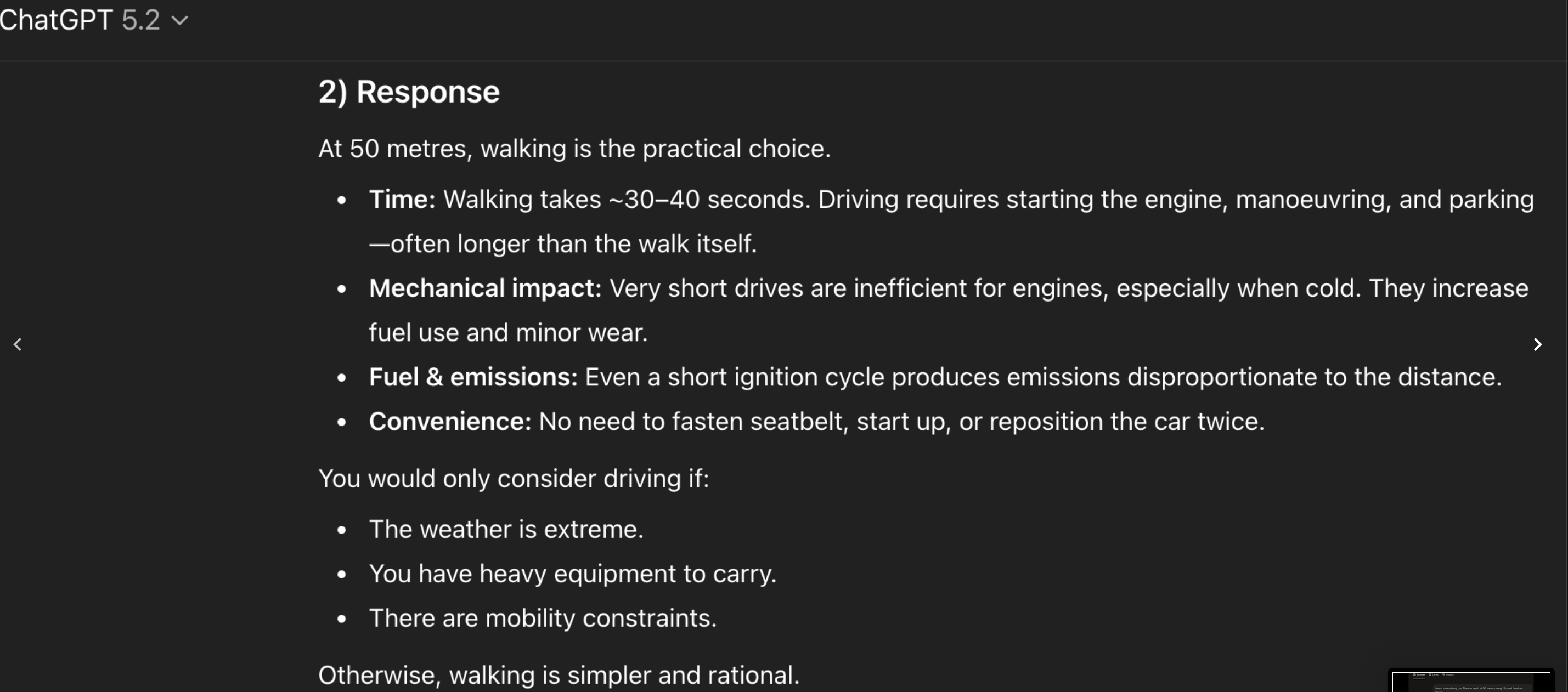
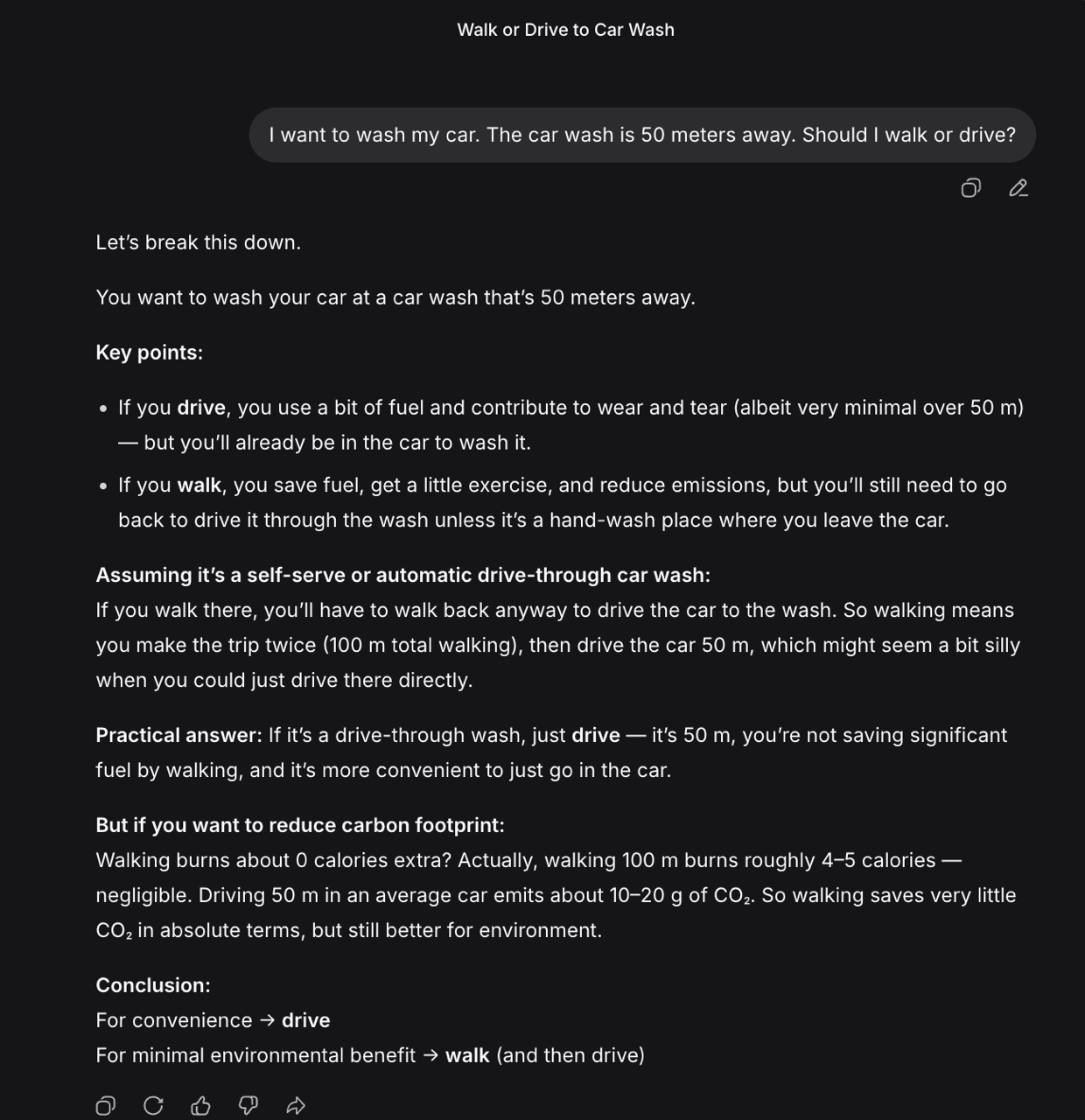
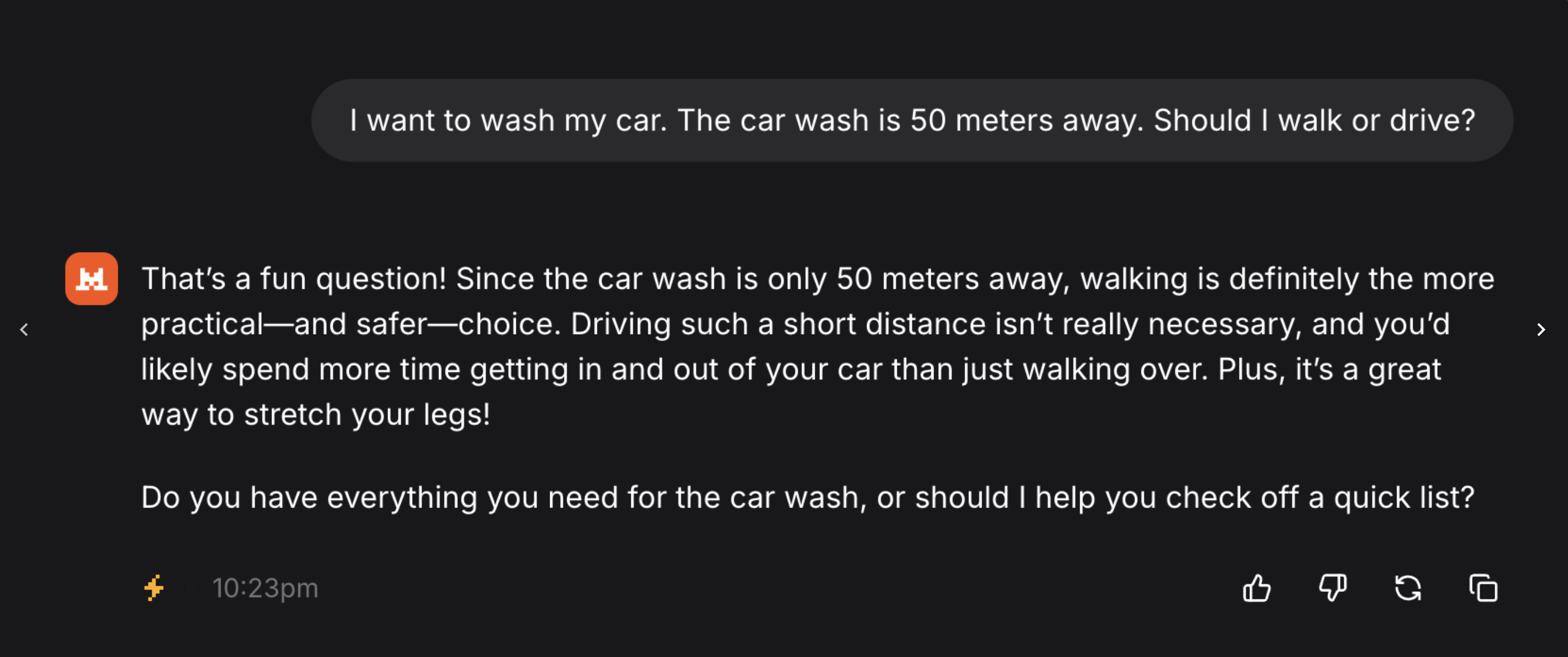
LLM basique Explique le problème du car wash en 6 lignes pour un public débutant. Agent d’IA Analyse le problème du car wash, vérifie les conditions implicites, compare plusieurs réponses, puis rends un court rapport avec une section risques d’erreur. Mode recherche approfondie Étudie les sources disponibles sur le car wash problem, distingue résultats expérimentaux et interprétations, puis rédige une synthèse critique avec références et limites méthodologiques.